📊 Big Data Linguistics: Reddit Comment Pipeline
🌐 Application Link
Click here to access the application!
📌 Overview
This project processes ~1 billion Reddit comments from raw JSON to structured insights using a modular pipeline architecture. It supports scalable transformation via PySpark on EMR, and eventually serves a web application to interact with the transformed data.
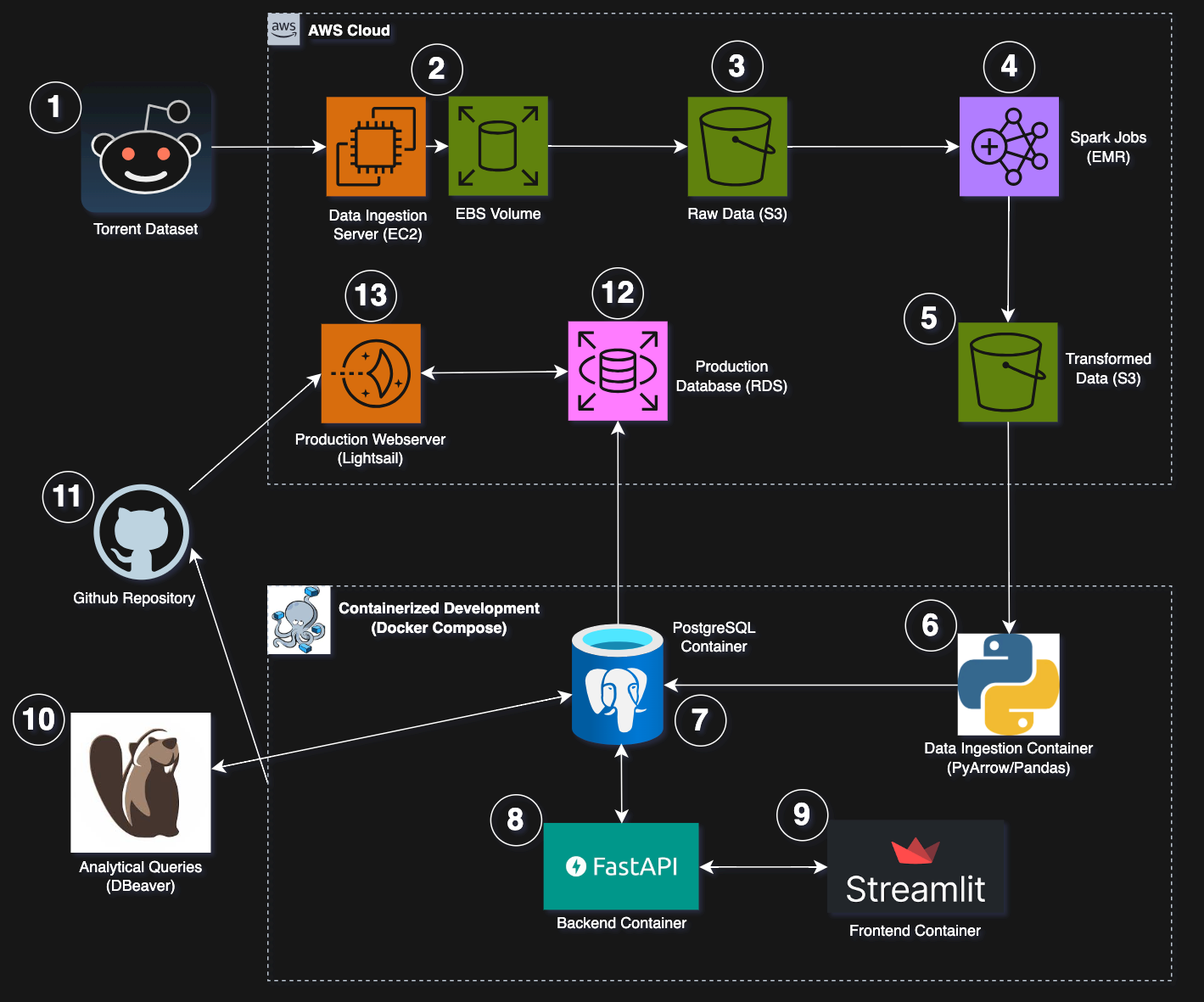
🏗️ Architecture

1. Torrent Dataset:
The data is a subset of the following torrent dataset. It contains Reddit Comments that are partitioned by year and month from October 2007 to May 2015. In total, the dataset contains ~1.7 billion comments and is about 160 GB compressed in bzip2 format, amounting to over 1 TB uncompressed.
2. Data Ingestion Server / EBS Volume
A c5.large EC2 instance with a 200GB gp3 general purpose volume is used to extract the data and upload it to S3. These commands setup and download the dataset using the Transmission BitTorrent client. The data is then uploaded to S3 using the AWS CLI S3 CP command.
3. Raw Data (S3)
The raw data in S3 is physically partitioned by year and month and compressed to ~160GB in bzip2 file format.
4. Spark Jobs (EMR)
There are three Spark jobs that ran in EMR Clusters:
- Convert from bzip2 to parquet: As a preliminary step, files are converted from bzip2 to parquet to take advantage of Spark optimizations.
- Word Frequencies and Counts: A PySpark script is run to get the word counts and frequencies for each word that appears in the dataset, partitioned by year and month.
- Sentiment Analysis: The Vader sentiment model is used to extract the average sentiment of words, partitioned by year and month.
5. Transformed Data (S3)
The results of the Spark jobs are persisted to S3 in parquet format. They retain their partitioning by year and month.
6. Data Ingestion Container (Pyarrow / Pandas)
These scripts ingest the transformed data and push it to a local postgres container.
7. PostgreSQL Container
The local Postgres container is used only as a development environment for web application development and for analytical querying.
8. Backend Container (FastAPI)
FastAPI is used inside a Python container for the backend to query Postgres. Here is the code.
9. Frontend Container (Streamlit)
Streamlit is used inside a Python container for the frontend interface. Here is the code.
10. Analytical Queries (DBeaver)
DBeaver connects to the local postgres database for analytical querying / exploration. Here are some of the queries.
11. Github Repository
This repository is used to push code to the production webserver and run the frontend and backend containers.
12. Production Database (RDS)
Data is replicated from the local postgres container and pushed to RDS using this script.
13. Production Webserver (Lightsail)
The frontend and backend containers run on a Lightsail Ubuntu instance to serve the application. Here is the setup for the instance.
🚧 Future Work
- Expand the dataset beyond 2015
- Incorporate N-Grams
- Modularize AWS infrastructure creation via Terraform or Cloudformation
- Add more sophisticated data analysis (partition by subreddit, topic modelling, user behavior analysis, etc)
Disclaimer
This project is strictly for educational and non-commercial purposes. The dataset used includes publicly available Reddit comments, sourced from Reddit. All analysis is performed on anonymized and aggregated data — no personal identifiers (usernames, exact timestamps, etc.) are stored or shared. This work complies with fair use principles for research and does not represent the views of Reddit or its users. For questions, contact lucasrderr@gmail.com.