Wikipedia-Clickstream
Overview
In this project, I use the Wikipedia Clickstream Data Dump to simulate a real-time data stream. I use Apache Kafka for ingestion, Apache Flink for processing, PostgreSQL for data storage, Metabase for real-time analytics, and Docker-Compose for orchestration. Additionally, I used Random User API to generate fake user data, enriching clickstream dataset with realistic user information.
How to Run Locally
-
Make sure you have Docker and Python installed on your device.
-
Clone this repository:
git clone https://github.com/lderr4/Wikipedia-Clickstream-Data-Engineering.git -
Navigate to Project Directory:
cd Wikipedia-Clickstream-Data-Engineering -
Build and run the project with one command (this should take a few minutes). You will be navigated to the Apache Flink UI. Confirm that the job is running.
make runThe UI should look like this:

-
To confirm the entire system is working correctly, use this command to check the number of rows in the users and clicks tables:
make count-rowsThe users table should have 5000 entries; the clicks table should be getting continually populated.

-
Optionally, you can run this command to start up metabase.
make Metabase
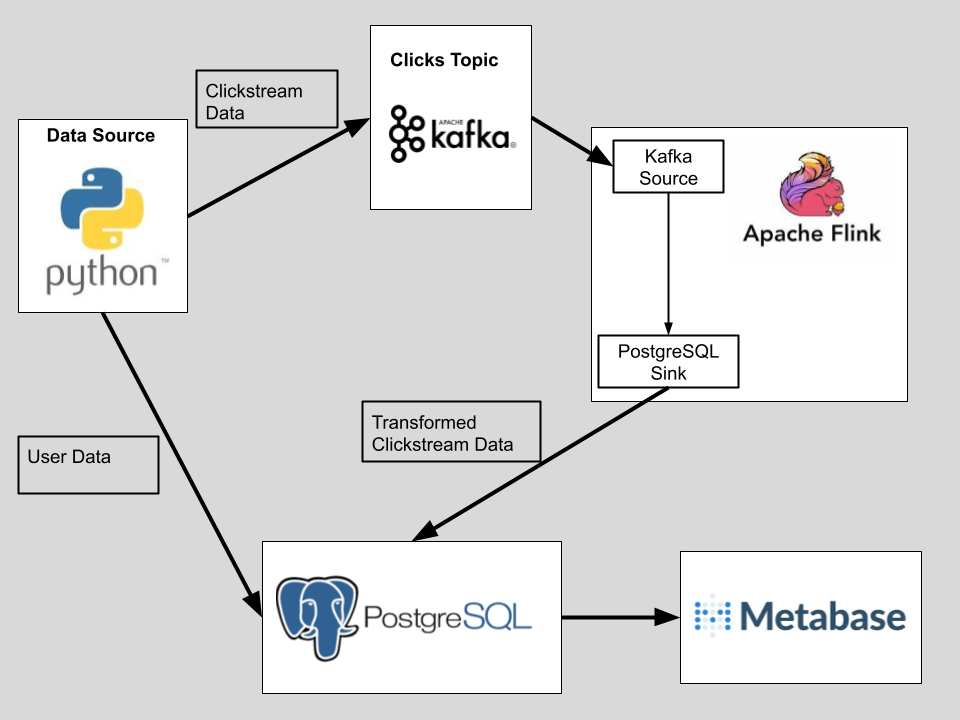
Architecture Diagram

Python Data Source
Simulate a data source by producing fake click data and sending it to the kafka topic. The data is taken from the Wikipedia Clickstream data dump and simulates realistic click probabilities. Additionally, the fake user API is used to generate a fake user table with 5000 rows. Each click is given a random user from the user table.
Apache Kafka
Apache Kafka serves as a message broker with its log-based queueing system, capable of handling high throughput data streams. The clicks data is sent to the clicks topic.
Apache Flink
Apache Flink is responsible for processing the data sent to the Kafka topic and inserting into the PostgreSQL database. A Kafka source and a JDBC PostgreSQL sink are set up with their respective Jar connectors, allowing Flink to interact with the Kafka topic and the PostgreSQL database simulatneously. Much like Apache Spark, Apache Flink runs with a distributed architecture utilizing Job Manager (Master) and Task Manager (Worker) nodes. In this project, I use two Task Manager slots, allowing for parallel processing of the incoming clickstream data.
PostgreSQL Database
My PostgreSQL setup utilizes the following schema.

Metabase Dashboard
Additionally, I have created a Metabase dashboard which refreshes every minute, showing real-time analytics of the fake data stream. Unfortunately, Metabase dashboards aren’t compatible with github because they are saved as database volumes. Regardless, I will share my screenshots here.

